
Linux Hardening
State of Linux Snapshot Fuzzing
What is snapshot fuzzing ?
Fuzzing is a well-established technique for finding software vulnerabilities, and snapshot fuzzing represents a significant advancement, enhancing efficiency and expanding the scope of testable software. Snapshot fuzzing is particularly valuable in application security where it enables thorough black-box testing of applications, regardless of their complexity. Its ability to significantly reduce the overhead associated with traditional fuzzing makes it a powerful tool for identifying vulnerabilities in real-world applications.
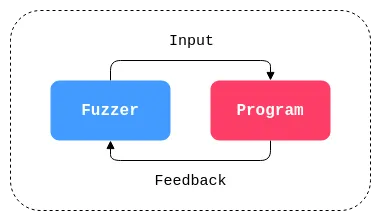
Snapshot fuzzing achieves its efficiency by creating a snapshot of the target application at a specific point in its execution. This snapshot encapsulates the application’s state, allowing for rapid restoration and repeated testing without incurring the cost of a full restart.
This technique is especially impactful when dealing with applications that have long initialization routines or require complex state setup, as it allows fuzzers to focus on testing the vulnerability-prone sections of code.
For instance, when testing a network service, a snapshot can be taken immediately before the packet processing logic, bypassing the time-consuming initialization of the network stack. This targeted approach drastically increases testing speed and efficiency.
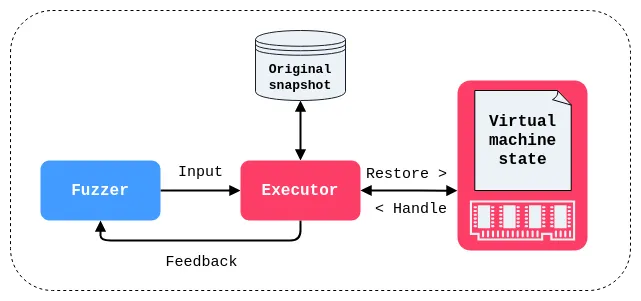
The ability to test applications directly from a desired state also opens up possibilities for exploring deeper program logic and uncovering vulnerabilities that would otherwise be difficult to reach with traditional fuzzing methods. It allows security researchers to target specific code paths and functionalities, making it possible to uncover vulnerabilities in complex applications that handle intricate data structures or stateful protocols, such as web browsers and network stacks.
Key techniques and approaches
Snapshotting
Snapshot fuzzing on Linux employs diverse techniques and approaches to improve black-box security testing. These techniques often leverage virtualization and system-level mechanisms to create and manage snapshots effectively. Here are some key approaches :
KVM-based snapshotting
This approach takes advantage of the Kernel Virtual Machine (KVM), a virtualization technology integrated into the Linux kernel. A notable example of this technique is Snapchange, an open-source framework designed to simplify snapshot-based fuzzing. It operates by taking a snapshot of a running virtual machine’s physical memory, preserving its exact state. The framework utilizes KVM’s ability to efficiently restore these snapshots, enabling rapid iteration during fuzzing. This method is particularly well-suited for targeting Linux-based binaries and systems.
Similarly, Nyx, another prominent snapshot fuzzer, utilizes KVM to accelerate the snapshotting process. It further distinguishes itself through its use of “affine types”, a mathematical concept that helps reason about the relationship between program inputs and their corresponding memory locations. This allows Nyx to efficiently determine which parts of memory need to be reset or modified for each fuzzing iteration.
See also other fuzzers like Barbervisor or Applepie which are custom-made hypervisors built upon other technology stacks.

Userspace snapshotting
This approach focuses on capturing and restoring the state of a user-space process, as opposed to an entire virtual machine. CRIU (Checkpoint/Restore in Userspace) is a Linux utility commonly employed for this purpose. CRIU enables the saving and restoring of a running process’s state, including its memory, open files, and network connections.
FitM, a fuzzing framework highlighted in the sources, uses CRIU to create snapshots of both client and server processes when targeting network protocols. By snapshotting at specific points during network interactions, FitM can meticulously analyze how data is exchanged and potentially uncover vulnerabilities. This approach is praised for its speed and efficiency, as it avoids the overhead associated with full system snapshots.
Emulation-based snapshotting
Emulators provide a controlled environment for executing software designed for a different architecture or operating system. In the realm of snapshot fuzzing, emulators offer the advantage of intercepting and controlling system-level calls made by the target application.
QEMU, a popular open-source emulator, is frequently used in conjunction with fuzzers like AFL++ or LibAFL to facilitate snapshotting. For example, when a target application running inside QEMU makes a system call, QEMU can intercept it, providing an opportunity to save or restore a snapshot. This allows for granular control over the execution environment and enables techniques like fault injection to uncover security flaws.
Process-level manipulation
This approach utilizes system calls and debugging facilities available in Linux to control the execution of a process. Ptrace is a powerful system call that allows one process to observe and manipulate the execution of another process.
Tools like Coldsnap, a Python-based fuzzer, utilize Ptrace to create snapshots of the target application. Coldsnap identifies strategically important points within the target’s execution flow where snapshots are taken and restored, enabling efficient fuzzing of specific code segments. The process is further enhanced by integrating code coverage feedback to guide the fuzzer towards unexplored code paths.
Similarly, Coldsnap-Rust, a Rust implementation of similar concepts, utilizes the same technique but benefits from the performance advantages and memory safety offered by our lord and savior Rust. 🦀
Input generation
A variety of methods are employed for input generation, each with its own set of techniques and strategies. Here, we explore some of the key approaches :
Corpus-based mutation :
This method takes existing inputs from a corpus and applies mutations to generate new inputs. The corpus can be minimized to remove redundant inputs while preserving code coverage. For example, FitM uses afl-cmin to reduce the corpus size.
Mutations range from simple techniques like bit flipping to more sophisticated operations such as input extension (combining an input with fragments of other inputs or dictionary tokens), recursive replacement (replacing parts of an input with other fragments), and string replacement (replacing substrings with other strings from a dictionary). Take the GRIMOIRE fuzzer, it generalizes inputs by identifying and replacing constant values with placeholders, and then applies these mutations to the generalized forms to produce more meaningful variations.
The choice and combination of mutation operators depend on factors such as the input type, desired complexity, and past coverage information.
Generation from specifications :
This method utilizes a specification of the input format, like a bytecode program, to generate inputs adhering to a specific protocol, this is particularly useful for fuzzing interactive interfaces like hypervisors. These generated inputs can be further mutated to explore edge cases or unexpected interactions.
For instance, NYX uses this method with bytecode programs expressed as directed acyclic graphs (DAGs), enabling it to fuzz complex systems like hypervisors and operating systems. NYX also supports fuzzing ring-3 applications by handling environment variables, command-line arguments, standard input, and multiple files as inputs.
Pseudo-random instruction generation :
This technique generates sequences of instructions using a PRNG and feeds them to the target program. It is particularly suited for systems with well-defined instruction sets, such as emulators and virtual machines. So, by initializing the PRNG with a specific seed, deterministic fuzzing campaigns can be conducted, e.g : HYPER-CUBE employs this method with a fast non-cryptographic PRNG to create a potentially infinite stream of instructions. To make generated instructions more realistic, arguments like region IDs and offsets are interpreted modulo the available range.
Input-to-State correspondence (Redqueen) :
Redqueen is a fuzzing technique, not directly a method for generating inputs, but it influences the input generation process. It observes the correspondence between input values and their representation in the program state during execution. This knowledge is then exploited to overcome common fuzzing obstacles like magic bytes and checksums, guiding the mutation process to generate inputs that satisfy these constraints.
This technique is integrated into the kAFL fuzzer, uses lightweight program tracing and state inspection to achieve this, offering significant performance advantages over computationally expensive alternatives like taint tracking and symbolic execution. It has proven effective in fuzzing both kernel-space and userland targets without requiring source code or platform-specific knowledge. It is also optionally integrated in Snapchange.
Observed snapshot fuzzers often utilize a combination of these methods and techniques to maximize their effectiveness in uncovering vulnerabilities.
Comparative analysis with other fuzzing techniques
Snapshot fuzzing – by allowing the fuzzer to begin execution from a saved state rather than requiring a full restart for each input – can reach greater depth than traditional coverage-guided fuzzers, which frequently overwrite necessary early communication packets with random mutations.
For example, (and as we said in the introduction) when fuzzing a network service, a snapshot can be taken at the point of packet processing, bypassing the network stack initialization. This advantage is especially significant when dealing with stateful protocols, where maintaining a specific state is essential for progressing through the different stages of communication.
As we talked earlier, FitM, a coverage-guided fuzzer for complex client-server interactions, leverages this ability by taking a snapshot each time a new interaction is reached. This allows for more extensive exploration of the state space because :
- Targeted fuzzing: By restoring to a specific interaction point, fuzzing efforts can focus on that specific stage of the communication, increasing the likelihood of discovering vulnerabilities related to that stage.
- Probabilistic state fuzzing: FitM periodically reruns earlier snapshots, introducing variations in earlier communication stages that can uncover vulnerabilities triggered by specific state combinations.
Snapshot fuzzing also exhibits strengths when compared to purely white-box fuzzing techniques in its ability to effectively target applications without relying on source code access. White-box fuzzing, while powerful in its ability to leverage program internals for precise testing, is limited when dealing with closed-source software.
This advantage makes snapshot fuzzing a more versatile tool for security researchers tasked with testing a diverse range of applications, including proprietary software and systems where source code availability is limited or nonexistent.
While HYPER-CUBE, which is non-coverage-guided, initially demonstrated superior performance over coverage-guided alternatives in testing specific hypervisor components due to its high throughput, further research, as evidenced by NYX, revealed that coverage guidance does offer significant advantages in fuzzing complex devices with deeply nested conditions. This suggests that while high throughput is beneficial, it’s crucial to balance it with the precision and guidance offered by coverage feedback for effectively uncovering vulnerabilities in systems.
However, despite its speed, creating harnesses for special cases can sometimes be challenging. For instance, ASan-instrumented binaries and the lack of real support for 32-bit statically linked binaries often require patching the binary and restoring its original state before starting fuzzing, which can be cumbersome. Additionally, ASan-instrumented binaries need about 15 TB of virtual memory due to their shadow pages, making it difficult to save from a hypervisor point of view.

Challenges and research
Snapshot fuzzing, despite its advantages, encounters several challenges that researchers are actively working to overcome.
One prominent challenge is the inherent difficulty of state management in complex software. Deciding when to create a snapshot presents a significant hurdle: overly frequent snapshots introduce considerable overhead, while infrequent snapshots risk missing vulnerabilities tied to specific, fleeting states. Adaptive snapshotting, as exemplified by Snappy, is an area of active research that aims to dynamically determine the optimal snapshot frequency based on real-time analysis of program behavior. By dynamically adjusting the snapshotting strategy, adaptive techniques hold the potential to significantly improve fuzzing efficiency without compromising coverage.
Portability presents another significant challenge. Many existing snapshot fuzzing tools rely heavily on specific virtualization or system-level mechanisms inherent to their design. For instance, Snapchange leverages the KVM hypervisor, a core component of the Linux kernel, for its snapshotting capabilities. This dependence, while allowing for efficiency on systems where KVM is readily available, restricts its use on systems where such mechanisms are absent, incompatible, or operate under restrictions. Exploring and developing alternative snapshotting approaches that exhibit less dependence on specialized hardware or software environments is an ongoing area of research crucial for expanding the applicability of this technique.
Efficiently navigating the vast state space of complex applications poses a formidable challenge in snapshot fuzzing. The potential program states can increase exponentially, quickly rendering an exhaustive exploration impractical, especially for complex software. Researchers are actively investigating and developing techniques like state-space reduction and guided fuzzing to address this challenge. FitM, for example, tackles this challenge by employing a probabilistic approach to revisit previously captured snapshots, rather than adhering to a strictly linear execution path. This approach increases the likelihood of uncovering vulnerabilities that might otherwise be missed due to the sheer size and complexity of the state space. Further research explores incorporating symbolic execution or machine learning techniques to intelligently guide the fuzzer towards the most promising areas of the state space, optimizing resource allocation and potentially uncovering vulnerabilities more effectively.
Extending the capabilities of snapshot fuzzing to effectively target specific software components, particularly those operating at a lower level, is another significant avenue of research. While current tools excel in fuzzing user-space applications, targeting kernel-mode components such as drivers presents unique challenges. The complexity of kernel-level interactions and the critical requirement for system stability necessitate specialized techniques. Projects like kAFL have made notable progress in addressing these challenges by using virtualization-based snapshotting for kernel fuzzing. However, further research is essential to mitigate the inherent performance overhead and address the complexities associated with kernel-level interactions, ultimately improving the efficacy and practicality of kernel-mode snapshot fuzzing.
Conclusion
Snapshot fuzzing has emerged as a potent technique for enhancing application security testing on Linux, offering significant advantages in testing efficiency and depth, especially for complex and stateful applications. By enabling the rapid restoration of system states, snapshot fuzzing allows for extensive exploration of program behavior and the discovery of vulnerabilities that might otherwise be missed by traditional fuzzing methods.
Tools like Snapchange and wtf showcase the practical implementations of snapshot fuzzing, enabling security researchers and developers to integrate this technique into their testing workflows. Moreover, ongoing research into areas such as adaptive snapshotting, exemplified by Snappy, aims to optimize resource allocation and further enhance the efficiency of snapshot fuzzing. The development of tools like FitM demonstrates the potential of snapshot fuzzing in effectively testing complex, stateful network protocols, paving the way for more robust and secure network applications. Similarly, projects like kAFL are pushing the boundaries of snapshot fuzzing by adapting its capabilities to the complexities of the Linux kernel, highlighting its potential in securing even the most critical system components.
Despite these advancements, challenges remain. The inherent complexity of state management in large software, the dependence on specific virtualization or system-level technologies, and the vastness of potential program states all necessitate further research and innovation. Additionally, adapting snapshot fuzzing to effectively target specific components like kernel-mode drivers and further minimizing performance overhead are critical areas of exploration for future research. These ongoing efforts underscore the evolving nature of snapshot fuzzing and its potential to remain at the forefront of black-box application security testing on Linux.
Bonus : Triaging fuzzers
This table compares various fuzzing tools I have utilized in my research, emphasizing key aspects – without a strong reliance on scientific data. 😉
| Name | Note | Limitations | Ease to use | Speed | Documented | Maintained |
|---|---|---|---|---|---|---|
|
One of the best available hypervisor-based snapshot fuzzer |
|
|
|
|
|
|
|
What The Fuzz (Linux)
|
|
Linux is user-mode only |
|
Depends on backend |
|
|
|
Full execution traces (from Intel PT) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Resources
Those are all the resources I looked at when researching this subject :
Tools
- 0vercl0k/wtf : wtf is a distributed, code-coverage guided, customizable, cross-platform snapshot-based fuzzer designed for attacking user and / or kernel-mode targets running on Microsoft Windows and Linux user-mode (experimental!).
- awslab/snapchange : Lightweight fuzzing of a memory snapshot using KVM. An amazon blog post describes its usage.
- libafl_nyx :
libafl‘s front-end for the nyx fuzzing framework, which facilitates fuzzing in virtual machines such as qemu. This crate provides both the standalone mode and parallel mode. - Agnoctopus/Tartiflette : Snapshot fuzzing with KVM and LibAFL , see presentation slides.
- defparam/Coldsnap : Python Snapshot Fuzzer Example
- defparam/Coldsnap-rust : Rust Snapshot Fuzzer Example
- MozillaSecurity/snapshot-fuzzing : Custom Agent and Tooling for using LibAFL++ & Nyx with Firefox, read IPC Fuzzing with Snapshots
- Cisco-Talos/Barbervisor : Intel x86 bare metal hypervisor for researching snapshot fuzzing ideas, read Journey developing a snapshot fuzzer with Intel VT-x
- seal9055/sfuzz : High performance fuzzing using riscv to x86 binary translations and modern fuzzing techniques
- fgsect/FitM : FitM, the Fuzzer in the Middle, can fuzz client and server binaries at the same time using userspace snapshot-fuzzing and network emulation. It’s fast and comparably easy to set up
Blog posts
- FuzzingBook – The Black Box Tour : focuses on black-box fuzzing – that is, techniques that work without feedback from the program under test.
- Diary of a reverse engineer – Building a new snapshot fuzzer & fuzzing IDA
- Fuzzing Like A Caveman series
- Fuzzing Like A Caveman
- Fuzzing Like A Caveman 2: Improving Performance
- Fuzzing Like A Caveman 3: Trying to Somewhat Understand The Importance Code Coverage
- Fuzzing Like A Caveman 4: Snapshot/Code Coverage Fuzzer!
- Fuzzing Like A Caveman 5: A Code Coverage Tour for Cavepeople
- Fuzzing Like A Caveman 6: Binary Only Snapshot Fuzzing Harness
- Fuzzer Development series
- Introducing HyperHook: A harnessing framework for Nyx
Whitepapers
- Snappy: Efficient Fuzzing with Adaptive and Mutable Snapshots
- NYX: Greybox Hypervisor Fuzzing using Fast Snapshots and Affine Types
- HYPER-CUBE: High-Dimensional Hypervisor Fuzzing
- kAFL: Hardware-Assisted Feedback Fuzzing for OS Kernels
- REDQUEEN: Fuzzing with Input-to-State Correspondence
- GRIMOIRE: Synthesizing Structure while Fuzzing
Medias
Patrick Ventuzelo / @Pat_Ventuzelo
Théo Abel / @theoabel_
About Us
Founded in 2021 and headquartered in Paris, FuzzingLabs is a cybersecurity startup specializing in vulnerability research, fuzzing, and blockchain security. We combine cutting-edge research with hands-on expertise to secure some of the most critical components in the blockchain ecosystem.
Contact us for an audit or long term partnership!

