
applied AI for Cybersecurity
Benchmarking LLM agents for vulnerability research
AI agents appear to be a powerful tool for advancing vulnerability research and securing modern applications. At FuzzingLabs, we decided to take a deep dive into this topic to assess its real-world potential.
We conducted experiments by building AI agents using various LLMs, with the goal of identifying vulnerabilities in intentionally vulnerable codebases written in Python, Go, and C++.
This blog post summarizes our experimental setup, methodology, observations, and final results.
AI Agent Architecture
Instead of using a multi-agent system for vulnerability detection, we chose a simpler approach: directly evaluating LLMs based on their ability to detect vulnerabilities in a single pass by reading the source code.
Here’s the process we followed:
- Chunking the source files for processing
- Analyzing each chunk line by line to identify potential vulnerabilities, limited in this study to SQL Injection (CWE‑89), Cross‑Site Scripting (XSS, CWE‑79), Command Injection (CWE‑77), Weak Cryptography (CWE‑327), Buffer Overflow (CWE‑120), and File Inclusion (CWE‑98)
- Aggregating the discovered issues and comparing them with the ground‑truth list of known vulnerabilities
Each detected issue is compared on three parameters (file, vulnerable line, and CWE) against the ground truth for evaluation.
Results
Below are the final results of our experiments. Each row corresponds to a model, and the columns represent:
TP (True Positives), FP (False Positives), FN (False Negatives), Final Score ( TP / (TP + FP + FN) )
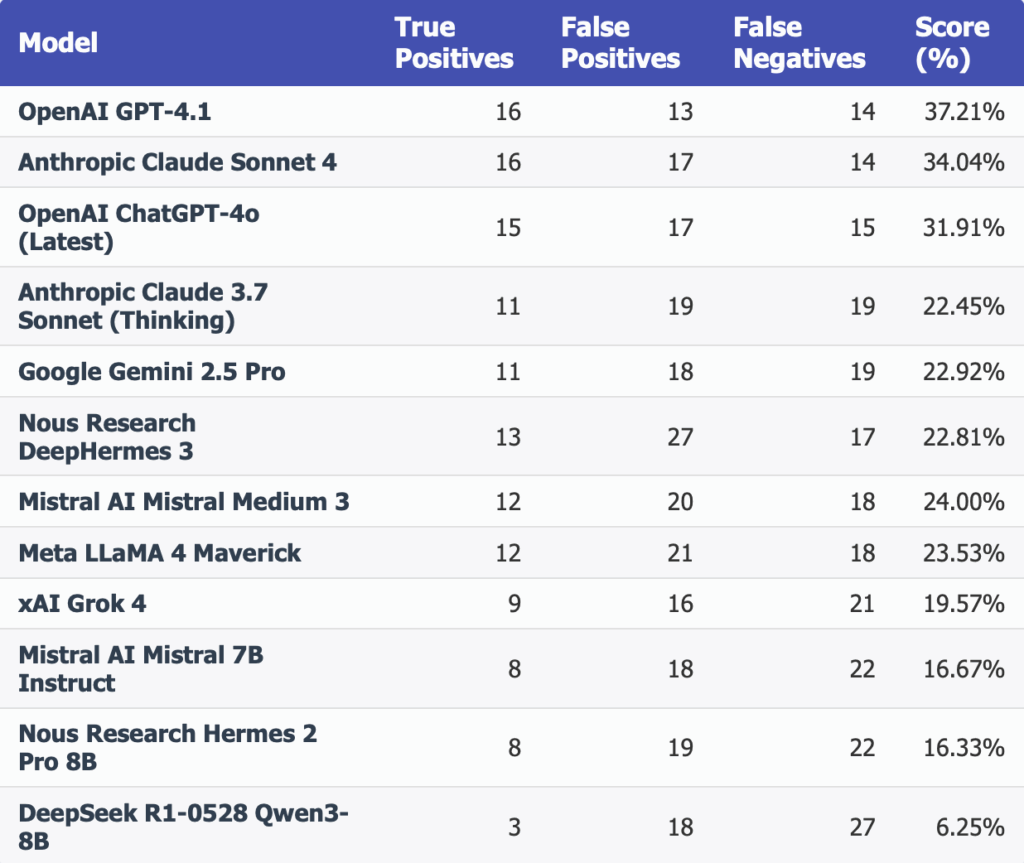
Observations
Closed‑Source Models Lead the Pack
OpenAI’s GPT‑4.1 (37.21 %), Anthropic’s Claude Sonnet 4 (34.04 %), and OpenAI’s ChatGPT‑4o (31.91 %) occupy the top spots, showcasing the strength of proprietary RLHF‑driven training for zero‑shot vulnerability detection.
Mid‑Tier Models Deliver Strong Performance
Mistral Medium 3 (24.00 %) and Meta’s LLaMA 4 Maverick (23.53 %) demonstrate that targeted instruction tuning and high‑quality data can yield competitive security‑analysis capabilities without the need for the absolute largest parameter counts.
Community‑Driven Variants Hold Their Own
NousResearch’s DeepHermes 3 (22.81 %) and Hermes 2 Pro 8B (16.33 %) sit solidly in the middle of the leaderboard, offering respectable performance that underlines the value of open‑community innovation in code‑security tasks.
Accuracy Remains Modest
Even the highest true‑positive rate falls below 40 %, indicating that a single, zero‑shot prompt is far from sufficient for comprehensive vulnerability detection and pointing to the need for richer prompting and orchestration techniques.
High False‑Positive Rates Across All Models
Every model reports double‑digit false positives (ranging from 13 to 27), suggesting they are adept at spotting potentially risky patterns but lack the contextual nuance to consistently filter out benign code without human‐in‐the‑loop review.
Training Quality Over Scale
While the largest closed‑source models lead, well‑tuned mid‑sized models closely follow, reinforcing that training methodology, data quality, and evaluation rigor are more decisive factors for practical security performance than sheer model size.
The Engineering Gap
Our benchmark reflects a minimal setup, prompting LLMs directly without advanced engineering or orchestration. The overall low scores across models should not be mistaken for a hard limitation of AI in security. Instead, they reveal the need for more thoughtful system design. Multi-agent collaboration, dynamic prompting, and iterative code analysis could substantially improve performance over this simple baseline.
Wanna dig into the details of the experiment ? You can check out the repo.
Yacine Souam / @Yacine_Souam
About Us
Founded in 2021 and headquartered in Paris, FuzzingLabs is a cybersecurity startup specializing in vulnerability research, fuzzing, and blockchain security. We combine cutting-edge research with hands-on expertise to secure some of the most critical components in the blockchain ecosystem.
Contact us for an audit or long term partnership!

