
Solana audit and tooling
Sol-azy: audit-friendly overviews for Solana programs
New feature Recap added to sol-azy! (See this article if you don’t know what is sol-azy)

What's new?
The new feature Recap turns an Anchor project into a compact, audit-friendly report that you can skim in minutes. It walks the repository, aligns the IDL with the #[derive(Accounts)] definitions, and writes a single Markdown file recap-solazy.md that summarizes each instruction across six signals: Instruction, Signers, Writable, Constrained, Seeded, and Memory.
Context / Problem solved
The first hour of any Anchor audit repeats the same motions: identifying the entrypoints, understanding the logic structure, mapping access control, etc. Doing this by hand means jumping back and forth across monstrous large Accounts definitions with stacked attributes, which is a slow and error-prone way to build an initial attack surface map.

You need a stable view of who can sign, what is writable, how writable state is bound, which accounts are PDAs (seeds), and where memory is allocated or reallocated.
Because in real Anchor codebases, the friction comes from the structure of the source itself. For example any signers, seeds, rules, etc., are all encoded in #[derive(Accounts)] structs, which are attribute-heavy blocks that can easily span 50 to 100 lines for a single instruction. Nothing is “hidden”, but the information density is so high that extracting only what you need becomes slow and mentally expensive.
You don’t struggle because the data is missing; you struggle because it’s embedded inside walls of attributes:
🦀
lib.rs
#[account(
init,
payer = payer,
seeds = [...],
bump,
token::mint = ...,
token::authority = ...,
constraint = foo.key() == bar.authority,
realloc = ...,
)]
pub account_a: Account,Multiply that by 8-12 accounts per instruction and repeat for every programs.
Even simple questions require scanning a large block:
- Who are the signers for this instruction?
- Which writable accounts matter and why are they safe to mutate?
- Is this PDA derived from deterministic seeds or supplied externally?
- Which SPL authority is actually controlling this token account?
- Does this instruction allocate or reallocate memory?
Anchor makes these patterns explicit, but not lightweight to parse visually.
A single missed has_one, a forgotten seed, or a misread SPL shorthand is all it takes to misunderstand the safety properties of an instruction.

Monorepos make this even worse.
You jump between multiple programs, each with similar naming patterns but subtly different invariants. Some instructions use generic forms like Context<‘_,‘_,‘_,’info, Foo<‘info>>, others use plain Context<Foo>. When pivoting between instructions, you constantly re-open the same files just to remind yourself which account was seeded, which one was SPL-bound, or which signer actually gates a writable account. The issue isn’t difficulty—it’s repetition and cognitive load.
From a vulnerability-research perspective, you want fast filters: “writable but not constrained nor seeded,” “memory grows via realloc,” “SPL accounts without helper bindings,” “multi-signer flows where authorities can be confused.” Building these filters from scratch on each repo costs cycles and increases the chance you miss edge cases.
Recap exists to remove that repetitive mental bookkeeping. It doesn’t judge correctness and it’s not a linter. It gives you a single, faithful table per instruction so you can (a) do first-pass reconnaissance quickly, and (b) keep a stable reference during the rest of the audit. That cuts down on code hopping, reduces context thrashing, and lets you spend time on the parts that actually require reasoning: constraint logic, CPI call chains, seed design, state invariants, etc..
The Feature
Recap produces a single file, recap-solazy.md, containing one compact table per Anchor program (each Anchor program found under target/idl/ gets its own section).
Each row represents an instruction, and each column captures a different axis of its access surface: Signers, Writable, Constrained, Seeded, and Memory.
Signers and Writable come directly from how the instruction is declared; you immediately know who must sign and which accounts can be mutated. This removes the constant need to jump back to handlers or large account structs just to confirm whether something is mutable or gated by a user, an admin, or a PDA-derived authority.
Constrained reflects the binding logic declared in #[account(…)]: has_one, address, explicit predicates under constraint = …, owner, as well as SPL shorthands like token::mint, token::authority, mint::decimals, mint::freeze_authority, and ATA derivation hints. All of these are reduced to compact tags so you see the relationships and safety assumptions at a glance instead of digging through gazillion-line struct definitions.
Seeded highlights accounts with explicit PDA derivations (seeds = […]). It answers the “which accounts are deterministic, and therefore which ones might be used as signers in CPIs?”.
Memory surfaces places where the program decides account size or mutates it: space, realloc, and realloc::zero. These are the instructions where you need to check who controls growth, how zeroing is handled, and whether resizing bypasses invariants.
All of this is extracted through lightweight parsing of the actual source (IDLs, #[derive(Accounts)] blocks, attributes, PDA seeds, memory directives). That’s nice to keep it open while auditing: it is a quick way to maintain context when pivoting between instructions, signers, PDAs, SPL wiring, and allocations.
Example: reading a table with multiple signers
Below is an example focused on the fanout program, (collected from the Helium protocol, an open source solana project), where one instruction uses two signers. This is taken from a real run; the names are representative of typical patterns.
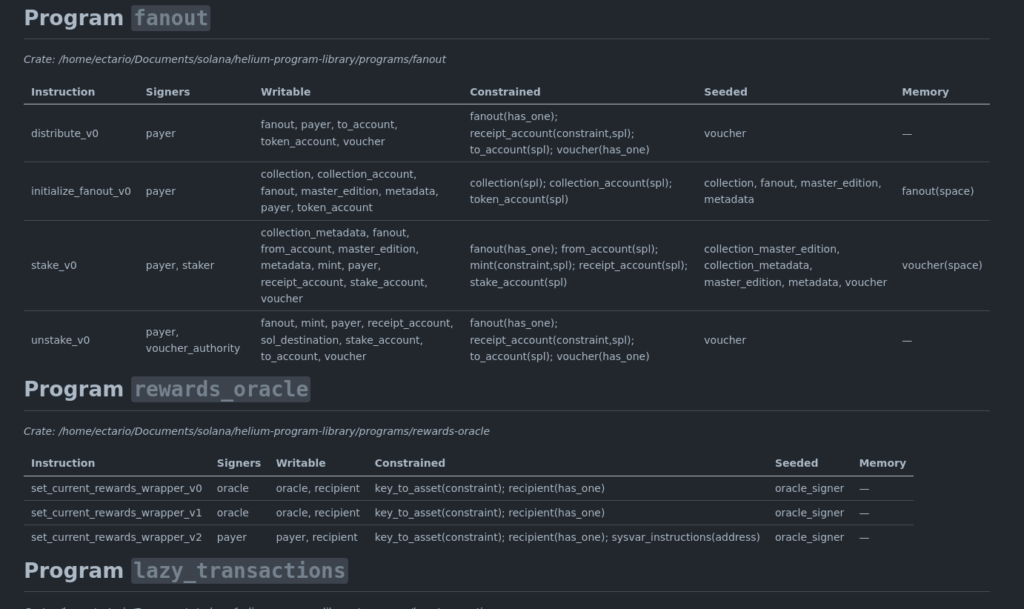
Let’s see the stake_v0 instruction, this row is doing several things at once. Recap shows two signers, payer and staker, it immediately suggest that the instruction depends on two separate authorities. That usually means one party funds the action while the other authorizes it, so it becomes natural to check how each signer is used inside the handler and which parts of the logic each one gates.
The Writable accounts include several SPL token and metadata accounts. Writable SPL accounts usually imply token transfers, balance updates, or metadata changes, so their presence signals where the state transitions and external effects likely occur.
The Constrained column shows a mix of has_one, SPL-derived constraints, and a custom predicate on mint. This combination hints that the instruction wants to tightly bind its token accounts and metadata accounts to a specific state object. For example, fanout(has_one) links the stake action back to a particular fanout instance, while SPL constraints ensure that token accounts actually correspond to the expected mint or authority. The extra constraint on mint suggests some domain-specific rule layered on top.
The Seeded column contains several PDA accounts: voucher, various metadata PDAs, and collection-related PDAs. Seeing multiple PDAs prompts a quick look at the seeds used throughout the program, checking whether they remain consistent and whether any of them could be influenced by caller input in a way that shifts authority or signer derivation.
Finally, Memory reports voucher(space), meaning the account is created with an explicit size. Any explicit space = … usually leads to checking who’s allowed to initialize or resize that account and whether its size depends on untrusted parameters.
Taken together, the stake_v0 row outlines the core structure of the instruction: dual authorities, several writable token paths, binding constraints, a cluster of PDAs, and explicit memory allocation. Without looking at the Rust yet, you already get a rough map of where the sensitive logic sits and which relationships deserve a closer read in the handler.
If you prefer to see the exact kind of definition Recap consumes, here is a representative Anchor snippet for only the stake_v0 instruction:
/// Stake an amount of membership tokens and receive a receipt NFT
#[derive(Accounts)]
#[instruction(args: StakeArgsV0)]
pub struct StakeV0 {
#[account(mut)]
pub payer: Signer,
pub staker: Signer,
/// CHECK: Just needed to receive nft
pub recipient: AccountInfo,
#[account(
mut,
has_one = membership_mint,
has_one = token_account,
has_one = membership_collection
)]
pub fanout: Box<Account>,
pub membership_mint: Box<Account>,
pub token_account: Box<Account>,
pub membership_collection: Box<Account>,
/// CHECK: Handled by cpi
#[account(
mut,
seeds = ["metadata".as_bytes(), token_metadata_program.key().as_ref(), membership_collection.key().as_ref()],
seeds::program = token_metadata_program.key(),
bump,
)]
pub collection_metadata: UncheckedAccount,
/// CHECK: Handled By cpi account
#[account(
seeds = ["metadata".as_bytes(), token_metadata_program.key().as_ref(), membership_collection.key().as_ref(), "edition".as_bytes()],
seeds::program = token_metadata_program.key(),
bump,
)]
pub collection_master_edition: UncheckedAccount,
#[account(
mut,
associated_token::mint = membership_mint,
associated_token::authority = staker,
)]
pub from_account: Box<Account>,
#[account(
init_if_needed,
payer = payer,
associated_token::mint = membership_mint,
associated_token::authority = voucher,
)]
pub stake_account: Box<Account>,
#[account(
init_if_needed,
payer = payer,
associated_token::mint = mint,
associated_token::authority = recipient,
)]
pub receipt_account: Box<Account>,
#[account(
init,
payer = payer,
space = 60 + 8 + std::mem::size_of::() + 1,
seeds = ["fanout_voucher".as_bytes(), mint.key().as_ref()],
bump,
)]
pub voucher: Box<Account>,
#[account(
mut,
constraint = mint.supply == 0,
mint::decimals = 0,
mint::authority = voucher,
mint::freeze_authority = voucher,
)]
pub mint: Box<Account>,
#[account(
mut,
seeds = ["metadata".as_bytes(), token_metadata_program.key().as_ref(), mint.key().as_ref()],
seeds::program = token_metadata_program.key(),
bump,
)]
/// CHECK: Checked by cpi
pub metadata: UncheckedAccount,
/// CHECK: Handled by cpi
#[account(
mut,
seeds = ["metadata".as_bytes(), token_metadata_program.key().as_ref(), mint.key().as_ref(), "edition".as_bytes()],
seeds::program = token_metadata_program.key(),
bump,
)]
pub master_edition: UncheckedAccount,
pub token_program: Program,
pub associated_token_program: Program,
pub system_program: Program,
pub token_metadata_program: Program,
}
Note: Recap is not a replacement for reading this struct or the handler logic. It just turns the parts you repeatedly need—signers, writables, bindings, PDAs, memory decisions—into a single row you can keep in view while you audit. You still do full instruction-level analysis; the table just reduces the amount of scrolling and re-parsing required to keep the big picture in your head. Of course, it also helps surface early “quick-win” candidates: rows where writable state appears with weak or no attribute-level bindings (no seeds, no has_one, no SPL authority ties, no signers) stand out immediately and often justify a first pass before diving into deeper control-flow analysis.
Technical architecture details
Recap is Anchor-first. It begins by verifying the target root contains Anchor.toml. It then discovers IDLs under target/idl/ and parses them, flattening nested account groups to leaf accounts and normalizing flags across Anchor versions so isSigner and signer are treated the same, and similarly for isMut and writable.
To pair an IDL with its source, Recap searches the workspace for crates that depend on anchor-lang. If the package name matches the IDL name, it uses that crate. Otherwise it computes instruction overlap: it scans the crate’s src/*.rs files for functions that take a Context<…> parameter and compares those function names with the IDL’s instruction names, picking the crate with the largest overlap. The scan looks for Context<…> anywhere in the parameter list and extracts the last top-level generic as the Accounts struct type. This handles common patterns like Context<Foo> as well as the verbose Context<‘_, ‘_, ‘_, ‘info, Foo<‘info>>.
Once the crate is chosen, Recap performs lightweight parsing on the concatenated src/*.rs strings. It finds #[derive(Accounts)] structs and, for each field, reads stacked #[account(…)] attributes exactly as written. Inside those attributes, it tags the presence of has_one, address, owner, constraint, SPL shorthands for token, mint, and associated token wiring, seeds = [ … ], and memory markers space, realloc, and realloc::zero. It then correlates those fields back to the IDL so that a constraint only appears in the report if the field is actually an account for that instruction. Finally, it renders the table and writes recap-solazy.md. Nothing is inferred beyond the presence of those markers; if a row shows “—” under Constrained or Seeded, it means Recap did not find those markers in the source for that account and instruction.
The CLI surface is deliberately small. Running cargo run — recap (or if you use a compiled binary under “solazy” that’s just solazy recap) analyzes the current directory and writes recap-solazy.md. Passing -d <directory path> analyzes another root but still writes the report to the current directory.
# analyze current directory -> writes ./recap-solazy.md
cargo run -- recap
# analyze a given path -> writes ./recap-solazy.md
cargo run -- recap -d ../my-solana-projectNote: Recap uses lightweight parsing rather than a full Rust compiler pipeline. It flattens the project’s .rs files and extracts attributes directly from the source. This approach keeps the tool fast and works well for standard Anchor patterns, including SPL shorthand. It is not intended to interpret custom macros or evaluate expressions hidden behind user-defined helpers, so highly unconventional setups may require a quick manual check.
Conclusion
Recap formalizes the reconnaissance phase of an Anchor audit. It extracts signer and mutability flags from the IDL, parses the bindings and seeds from the #[account(…)] attributes, highlights where memory is allocated or adjusted, and consolidates everything into a single Markdown report. The output stays deliberately factual: no interpretation, no heuristics, just the declarations already present in the program. For reviewers, this reduces the initial triage step dramatically. For developers, it offers a quick way to validate that writable accounts are properly bound, PDAs are clearly derived, and memory changes are rights.
Run it with cargo run — recap (or provide -d <dirpath> to target another directory), then open recap-solazy.md. A practical starting point is to look for writable accounts without corresponding has_one, address, or seeds entries. From there, dive into the instruction handlers and CPIs to understand the intended control flow. The report doesn’t replace a full audit, but it gets you oriented far faster.

Dimitri C. / @Ectari0
About Us
Founded in 2021 and headquartered in Paris, FuzzingLabs is a cybersecurity startup specializing in vulnerability research, fuzzing, and blockchain security. We combine cutting-edge research with hands-on expertise to secure some of the most critical components in the blockchain ecosystem.
Contact us for an audit or long term partnership!
