
Hardware virtualization
Introduction to KVM & Hardware Virtualization
Virtualization has become a huge part in production environments, in traditional IT or in the cloud, improving security, development cycles and maintenance. This technology is the cornerstone that allows us to build isolated sandboxes, drastically shorten the time it takes to provision new servers, and perform hardware maintenance with zero downtime through live migration. It also creates a whole new attack surface, that we’ll be introducing in this post.
At the heart of this capability lies the hypervisor, the software that creates and manages virtual machines. In the vast ecosystem powered by Linux, one solution stands out for its deep integration and performance: KVM. As a core feature of the Linux kernel itself, KVM effectively turns the operating system into a powerful, native hypervisor, establishing it as a foundational building block for a majority of today’s cloud platforms and virtualized data centers.
Hypervisors and their different types
A hypervisor, or Virtual Machine Monitor (VMM), is the software that creates and runs virtual machines. There are two main types of hypervisors:
- Type 1 (Bare-Metal) Hypervisors: These run directly on the host’s hardware, acting as a lightweight operating system. They have direct access to the system’s resources and are generally more performant and secure. Examples include VMware ESXi, and Microsoft Hyper-V.
- Type 2 (Hosted) Hypervisors: These run as an application on top of a conventional operating system. They are easier to set up and manage but introduce more overhead as they have to go through the host OS to access the hardware. Examples include VMware Workstation, Oracle VirtualBox, and QEMU.
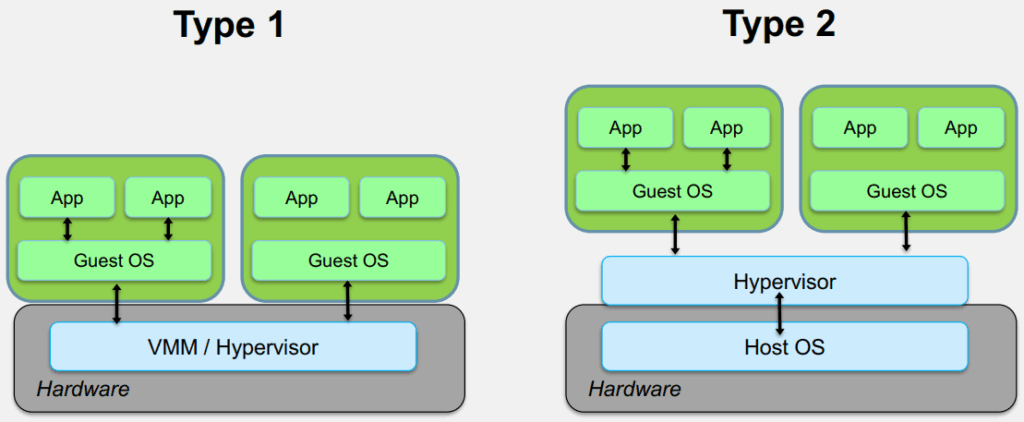
These two categories are not really well defined : KVM, being a part of the Linux Kernel, is kind of in-between the two, so a sort of type 1 and a half hypervisor. Also note that VMware Workstation and VirtualBox also push modules into the kernel, so they could be considered one and three quarter type hypervisors.
A Brief View of Virtualization techniques
1- Full Binary Emulation
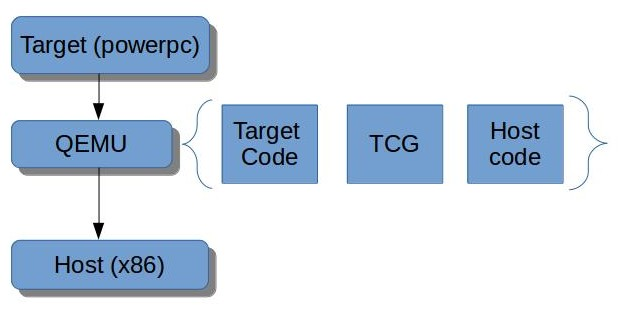
Full Binary Emulation is a powerful virtualization method that allows a host system to run a completely unmodified guest operating system, even one from a different CPU architecture.
The process is called Binary Translation (BT), where the emulator dynamically translates blocks of guest machine code (e.g., ARM) into instructions the host CPU (e.g., x86-64) can execute. This technique offers a strong security advantage: the entire guest environment runs inside a single, unprivileged userspace process on the host. Its main drawback behind its slowness.
Its ability to run cross-architecture code remains its defining feature. This technology is central to modern tools like QEMU, which uses its TCG IR (Intermediate Representation) for this translation.
2- Paravirtualization
To overcome the performance limitations of full emulation, paravirtualization was introduced.
This technique requires modifying the guest operating system’s kernel to make it aware that it is running in a virtualized environment. By doing so, the guest can directly communicate with the hypervisor, eliminating the need for complex emulation of hardware devices. VirtIO is a standard for paravirtualized devices, providing a set of common features for network, block, and other devices. vhost is a kernel-level backend for VirtIO that further improves performance by moving the virtio backend into the guest kernel. You can dive deeper into paravirtualization with this RedHat article.
3- Hardware Virtualization
The real game-changer for virtualization was the introduction of hardware support from CPU vendors.
The idea is to move security boundaries from software to the CPU itself (hence hardware-assisted virtualization), to enable the guest to run on the CPU itself, achieving near native speeds. The hypervisor’s role is reduced to managing the virtual machines and providing them with access to the physical hardware.
Intel’s VT (technical name VMX) and AMD’s AMD-V (technical names SVM/SEV) are sets of x86 processor extensions that enable the secure hardware-assisted emulation. ARM also provides virtualization extensions in its architecture. This technology significantly improves performance and allows for the virtualization of unmodified operating systems, including proprietary ones like Windows.
The introduction of additional hardware features, such as the IOMMU or TDP (generic term for two-dimensional paging, or nested paging, EDP for Intel, NPT for AMD), further enhanced the near-native performances.
Harware virtualization overview
Note : This section evokes CPU features such as MSRs, MMIO, APICs. If you are not familiar and would like to read on these topics, you may enjoy Ayoub Faouzi’s CPU Internals.
Let’s give a generic overview of how the VM running loop works on the hardware side. Although the vocabulary I’ll be using might change depending on implementation (AMD, Intel, ARM), the ideas pretty much stay the same.
The kernel (Virtualization instructions are privileged) asks the CPU to run a VM. This is done by providing beforehand the data needed to run the VM.
The CPU performs a “VMENTER”, and the VM runs on the raw CPU, but in its own “world” (different address space, etc), until it tries to execute an instruction that could break a security bundary (accessing a non-existing address, changing an MSR, addressing MMIO/PIO, etc).
When such an event happens, the CPU performs a VMEXIT and returns to the hypervisor, providing it with the VMEXIT reason and additional data. The hypervisor is charged to solve this exception anyway how it would see fit (emulate the instruction, pass the MMIO access to QEMU to let it emulate a network card, create a new address range for the VM, etc).
When the exception has been resolved, another VMENTER can be performed, resuming the VM execution, the exception having been transparently solved. To the VM, it seems nothing happened, and the instruction was correctly executed.
Getting into x86 & AMD’s SVM specifics
So far, we have been largely architecture-independent.. We will now dive into the x86 AMD implementation (although Intel’s is pretty close to AMD’s).
AMD’s AMD-V extension provides several instructions to work with virtualization. Amongst them is VMRUN, the instruction which performs the VMENTER. It expects in RAX the physical address of the VMCB, a 0x1000-byte structure that holds the configuration of the VM, created by the hypervisor (Intel doesn’t have such a struct, rather uses VMREAD/VMWRITE instructions to deal with this configuration in a blackbox way)
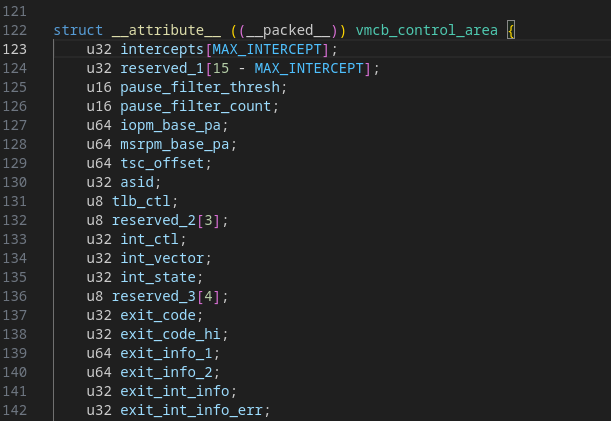
In the VMCB, notable fields are :
- Intercept vectors : tell the CPU wether a specific instruction must be intercepted and result in a VMEXIT
- Exit infos : filled by the CPU on VMEXIT to inform the hypervisor of the causes of the VMEXIT
- VM registers : the registers of the vCPU, updated upon VMEXIT by the CPU
SVM (Secure Virtual Machine, the technical name of AMD-V) also provides MSRs (Model Specific Registers) to configure the extension. Among them, a bit in EFER controls the activation of the virtualization extension, or the VM_HSAVE_PA MSR which (AMD Manual)
holds the physical address of a 4KB block of memory where VMRUN saves host state, and from which #VMEXIT reloads host state. The VMM software is expected to set up this register before issuing the first VMRUN instruction.
If you want more detail about the VMCB layout, to explore more in depth the technology, you can find it in the AMD64 Manual, Vol. 2 under Appendix B VMCB Layout.
Note : if you’d rather dive into Intel’s implementation, you can check out daax’s 5 Days to Virtualization: A Series on Hypervisor Development
The Linux Hypervisor : KVM
KVM (stands for Kernel Virtual Machines) is the Linux kernel hypervisor, meaning integrated in the Linux kernel. It does not however run the host Linux kernel, as Hyper-V VBS does for Windows.
As it is used in the AWS & Google Cloud architectures, and has a very unique attack surface mixing software and hardware, KVM is a very important target to properly secure.
Google for instance is very keen on securing it, providing the kvmCTF with a $250,000 reward for a full x86 Intel escape. They are also doing hardening – 7 ways we harden our KVM hypervisor at Google Cloud – and security research on KVM (Felix Wilhelm’s An EPYC escape: Case-study of a KVM breakout).
Specificity
KVM as a hypervisor is specific in the sense that it only provides an API to create VMs. It does not work out of the box, it needs a userland process to manage the VMs (VMM). That’s why you’ll often find KVM in your favorite VMM under the “accelerator” option.
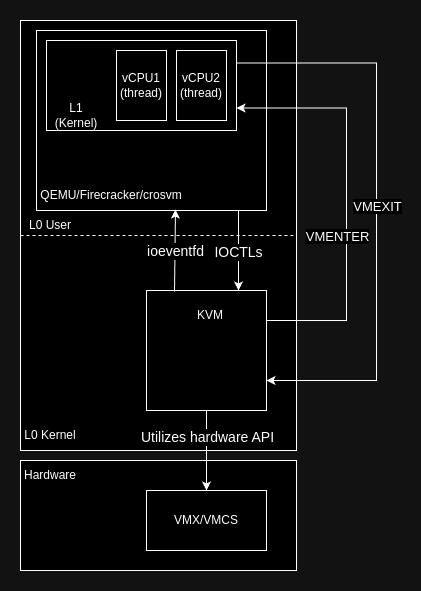
With Qemu as the VMM, it’s traditionally called Qemu/KVM, with the option -cpu host -enable-kvm, and replaces TCG. It can also be used with libvirt or as an accelerator for VirtualBox. Cloud providers tend to avoid using Qemu/KVM because of its overhead and huge attack surface with its emulated devices. Amazon for instance developed Firecracker for efficient and safe microVM management.
KVM exposes to userland a set of IOCTLs to create and manage virtual machines. Its role is only to manage the emulation features that require hardware privileged access, and act as a bridge between the VMs and the userland VMM.
Attack surface
As with any software, analyzing and reducing the attack surface is paramount to its security. Being “only” an API to create VMs, and not handling hardware emulation or the likes (copy-paste, etc), KVM attack surface is quite small, specific and interesting.
The threat-model for hypervisor generically considers that the attacker controls the guest kernel (by being root or exploiting an LPE). It asks : Can the attacker take control of the Host from the Guest kernel (VM Escape) ?
The usual approach to this is exploiting QEMU (the VMM) vulnerabilities, resulting in a host userland takeover. As I’ve said, AWS have been reducing this surface by creating Firecracker (notably in Rust – but not bug-proof, see this chompie article). However, KVM per se residing in the kernel, a successful KVM exploitation would result in host kernel exploitation.
The VM is allowed to run free, unless a VMEXIT is triggered. When this happens, KVM must react to it to allow the VM to run seamlessly. The attack surface is then all the actions the guest (kernel) could take that would result in a VMEXIT and KVM logic being triggered.
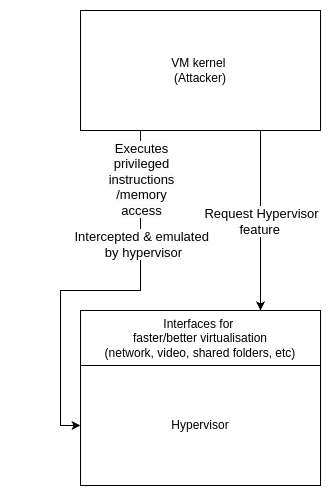
Such an interaction could be the hypercall interface, akin to what syscalls are between userland and kernel-land. In a paravirtualization setup, when the guest is aware it is run inside a hypervisor, it may use (for AMD) the VMMCALLinstruction to perform a hypercall. KVM only provides very few hypercalls (x86 has 6 active), so this particular attack surface is very limited. Other examples involve emulated instructions, particular CPU modes (SMM), nested virtualization (will be explored in the nexts blogposts !), MSRs access, etc.
Note : For the purpose of paravirtualization, KVM sets CPUID 0x40000000 to KVMKVMVKM to inform the guest of the paravirtualization (in arch/x86/include/uapi/asm/kvm_para.h).

Another KVM attack surface is hardware configuration : since a lot of security boundaries are delegated to the CPU, the VM security configuration must be configured right to avoid security violations. For instance, the AMD VMCB contains a MSR bitmap intercept field, which tells the CPU which MSR read/write must be intercepted. Failure to properly handle these configurations will result in VM escape, as shown by Felix Wilhelm in the before-mentioned P0 article (exploiting a TOCTOU in nested virtualization to create an overly-privileged VM with arbitrary MSR read/write, and use it to take control of the host).
Conclusion
This concludes this first part and introduction to hardware virtualization and KVM. The next part(s) will be dedicated to the KVM debugging setup, and the creation of a nested virtualization fuzzer.
Stay tuned !
Antoine Assier de Pompignan – Gravis
About Us
Founded in 2021 and headquartered in Paris, FuzzingLabs is a cybersecurity startup specializing in vulnerability research, fuzzing, and blockchain security. We combine cutting-edge research with hands-on expertise to secure some of the most critical components in the blockchain ecosystem.
Contact us for an audit or long term partnership!
