
Memory management
Introduction to modern memory management
The goal of this article is to present the functioning of volatile memory in general on our modern computers.
Physical Organization
Before discussing volatile memory, it is important to understand the basics of how a computer operates. A PC is composed of several electronic components and peripherals that interact with each other. One of the main components, the motherboard, enables communication between all these components. These communication channels are generally called computer buses.
CPU
The main components on the motherboard are the CPU – which executes sequences of instructions – and volatile memory – which temporarily stores programs and their data. The CPU accesses the memory to retrieve the instructions to execute.
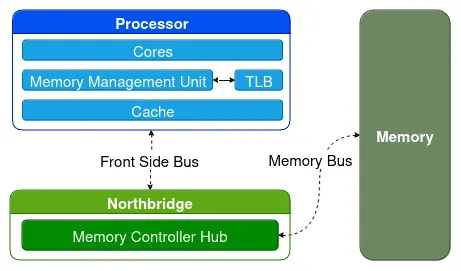
Reading from memory is often very slow compared to the CPU’s internal memory. Consequently, modern systems adopt multiple layers of very fast memory: caches.
 Info
According to the course CS 131: Fundamentals of Computer Systems, L1/L2 caches are accessible in 1-3ns, the L3 cache in 12ns, and the main memory in 63ns.
Info
According to the course CS 131: Fundamentals of Computer Systems, L1/L2 caches are accessible in 1-3ns, the L3 cache in 12ns, and the main memory in 63ns.
Each cache level (L1, L2, …) is slower than its predecessor but offers more space. In most systems, these caches are implemented directly within the processor and each of its cores.
If a requested data is not found in a cache, it must be fetched from the second-level cache or the main memory.
Memory Management Unit (MMU)
The MMU (Memory Management Unit) is a hardware component that translates the virtual addresses used by the processor into physical addresses. To perform this task, the MMU must be configured using special system registers, while memory structures maintaining the virtual-to-physical mapping must be defined and continually updated by the operating system.
If the MMU fails to resolve a requested virtual address, it triggers an exception (non-maskable, cpu-synchronized, non-reconfigurable and can’t be ignored) to notify the operating system to update the associated memory structures.
⚠️ Warning
The MMU requires strict compliance of the memory structure's format and topology with the configuration requirements of the Instruction Set Architecture (ISA) and its own. Otherwise, it generates an exception and aborts the address translation.
The translation process may involve up to two distinct translations, both performed by the MMU: segmentation, which converts virtual addresses into segmented addresses, and paging, which converts segmented addresses into physical addresses. Some architectures use one or the other, while others use both.
These points will be detailed later in the article.
Generally, during system startup, the MMU is virtually disabled, and all virtual addresses are identically mapped to physical addresses. This allows the operating system to boot in a simplified memory environment and provides time to properly configure/enable the MMU before launching other processes.
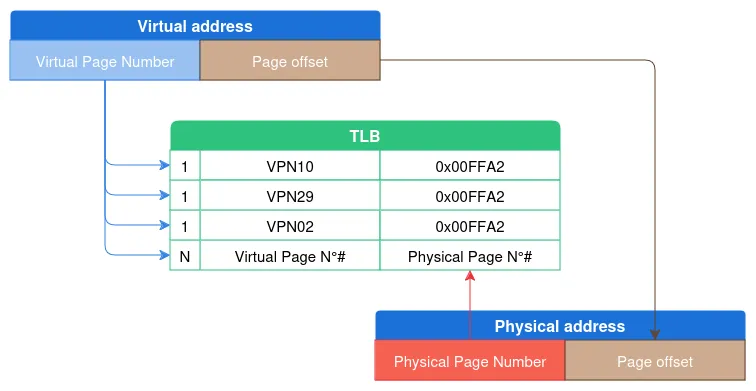
Translation Lookaside Buffer (TLB)
An address translation may require several memory reads, making the operations slow. To mitigate this, the processor uses a special cache called the Translation Lookaside Buffer (TLB). Before beginning a translation, the MMU checks whether the TLBs contain a previously resolved virtual address and, if so, directly returns the corresponding physical addresses.
Info
Each TLB contains only a few hundred entries (typically 4096), yet the hit rate is incredibly high (~99%).
Direct Memory Access
To improve the performance of modern systems, there are I/O components capable of transferring data directly from the memory stored in RAM without CPU intervention: this is known as Direct Memory Access (DMA).
Before DMA was invented, the processor handled every memory transfer. For large data transfers, the CPU quickly became a bottleneck. On modern architectures, the CPU can initiate a data transfer by allowing the DMA controller to manage the process. A peripheral can also perform a transfer independently of the CPU.
Beyond its obvious impact on performance, DMA is also significant in memory forensics as it allows direct access to physical memory from a peripheral without running third-party programs on the machine.
I recommend the article Malekal – DMA (FR) or the post Geeksforgeeks – DMA to learn more.
Random Access Memory (RAM)
A machine’s main memory is implemented with Random Access Memory (RAM), which stores the code and associated data manipulated by the CPU.
In contrast to a Sequential Access Storage, which reads data sequentially, Random Access refers to the characteristic of having constant access time regardless of where the data is located on the component.
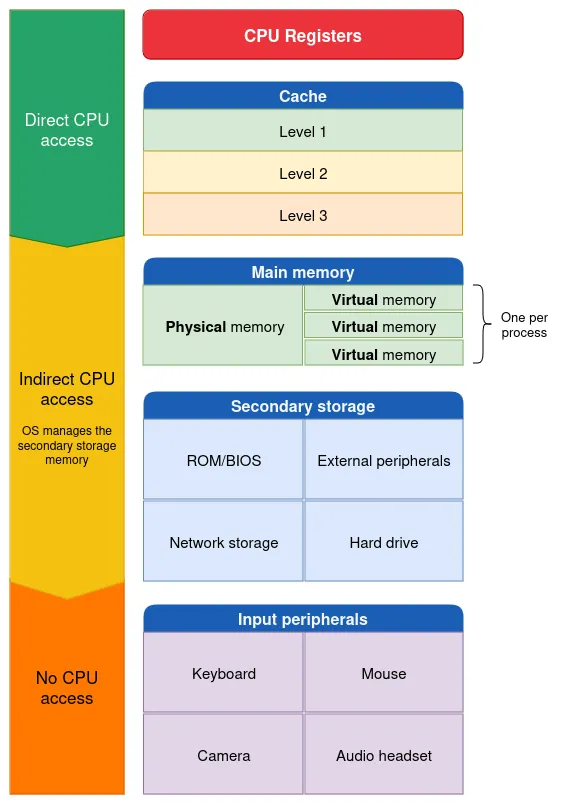
Main memory is also referred to as Dynamic RAM (DRAM). It is called dynamic because it uses the differential between a charged and discharged capacitor to store a bit of data. To remain charged, the capacitor must be periodically refreshed by the memory controller (see figure 1).
RAM is called volatile memory because it requires power to keep data accessible. When the machine is powered off, all data is lost. Or is it? The study Lest We Remember: Cold Boot Attacks on Encryption Keys demonstrates that RAM remains charged for a few seconds—or even minutes—after power loss.
Logical Organization
To extract structures from physical memory, one must have a clear view of the programming model the CPU uses to access memory. We’ve seen the hardware aspect; now we will focus on the logical organization of memory as exposed to the operating system.
For the CPU to execute instructions and access data stored in main memory, it must reference a unique address. An address can be 64 bits (8 bytes) or 32 bits (4 bytes) depending on the architecture.
📌 Info
Address space refers to the range of valid addresses used to identify data stored in a finite memory allocation.
The unique and continuous address space exposed to a running program is called the Linear Address Space, or more commonly the Virtual Address Space (VAS). The term Physical Address Space (PAS) refers to the addresses in physical memory. These physical addresses are obtained by translating virtual addresses using one or more page tables (variable-sized blocks of bytes depending on the system, e.g., 4k, 8k, etc.).
Virtual Memory
The abstraction of virtual memory offers numerous advantages, allowing programs to be written as if they have complete and unlimited access to main memory, regardless of actual usage or the presence of other programs. It enables multiple processes to run simultaneously without concern for the physical memory layout, which may differ between machines. Virtual memory also isolates and protects processes, preventing malicious, unauthorized, or poorly programmed applications from accessing the memory of other running programs.
This system also allows a program to allocate memory beyond the limits of PAS by mapping part of a process’s VAS to secondary storage (typically an SSD/HDD, see memory swap).
This abstraction is implemented in different architectures using two distinct methods:
- Segmentation
- Paging
Segmentation
Segmentation, the older of the two methods, was originally developed to organize and protect running programs.
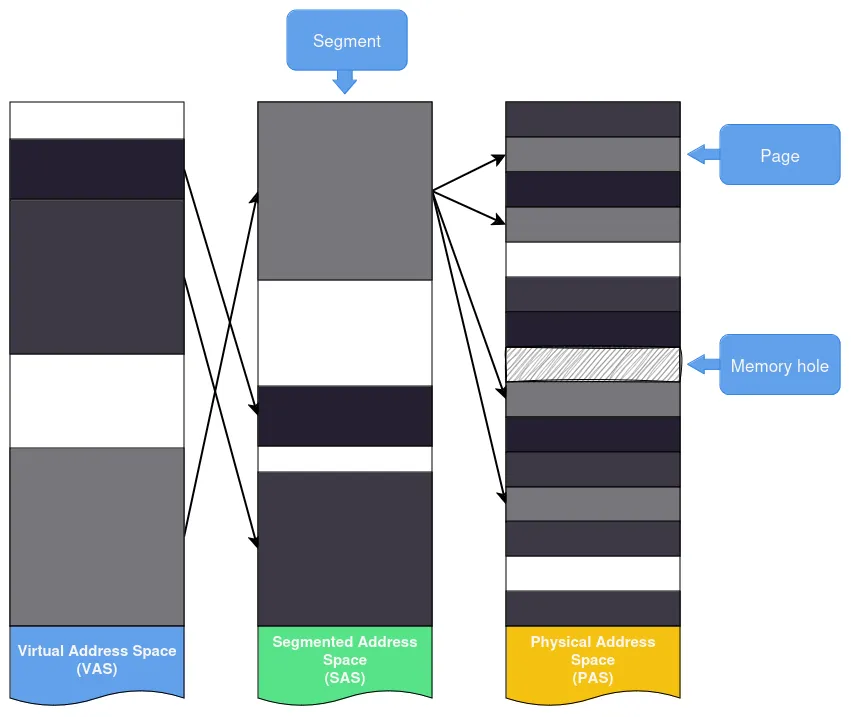
Its purpose is to divide a process’s VAS into one or more logical units, called segments, of varying sizes and access permissions by mapping them into another address space called the Segmented Address Space (SAS).
Typically, segments follow the internal structure of the program they represent: for example, a process may be divided into two different segments containing the code and the data, respectively.
However, segmentation does not allow optimal use of available memory: if segments from multiple programs are directly mapped onto physical memory, the PAS begins to fragment, and eventually, it becomes impossible to allocate sufficiently large chunks for new segments.
To address this issue, we must first introduce the concept of paging.
📌 Info
Memory holes are regions of physical memory that cannot be used for storage purposes (e.g., MMIO, regions reserved for specific components, ROMs, unassigned regions, etc.).
Paging
A page is a continuous block of memory of fixed size (usually small: 4k, 8k, etc.). The SAS is then divided into a set of pages—called virtual pages—and a mapping mechanism is defined to link them to pages in the PAS (referred to as physical pages or page frames), as shown in figure 4.
This technique, known as paging, significantly reduces physical memory fragmentation and helps maximize the utilization of available resources. It is essential to understand that both segmentation and paging require in-memory data structures or dedicated CPU registers configured by the operating system and utilized by the MMU.
Before exploring the most common paging techniques on the majority of architectures, it is necessary to describe page tables, page directory tables, and huge pages.
Page tables are data structures used in a virtual memory system. They establish a correspondence between virtual and physical addresses.
The page number of an address is typically determined from the most significant bits of the address, while the remaining bits provide the offset of the memory location within the page. The page table is usually indexed by the page number and contains information indicating whether the page is currently in main memory, where it resides in main memory or on disk, along with certain flags that will be covered in a future article.
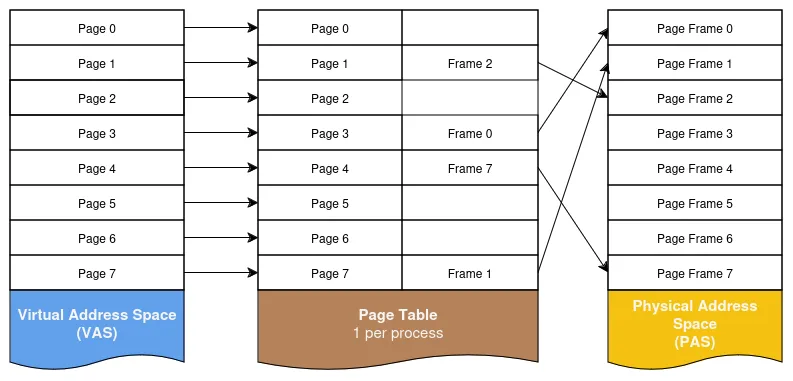
Since page tables cannot contain all the addresses of the VAS, page directory tables are used. These are also data structures, and their entries point to page tables. This allows for a second level (or more, depending on the architecture).
Huge pages are primarily used for virtual memory management on Linux. As the name suggests, they allow managing large-sized memory pages in addition to the standard 4 KB page size. Pages as large as 1 GB can be defined !
At system startup, applications can reserve portions of memory using huge pages. These reserved memory regions will never be swapped out, which can significantly enhance application performance.
Using large pages simply means requiring fewer pages overall. This greatly reduces the number of page tables the kernel needs to load. It improves kernel performance since there is less to manage, resulting in fewer read/write operations to access and maintain them.
There’s still a lot to understand before we can fully grasp how memory management works, but we’ll get to that in a future article !
Sources
Many of the diagrams and text presented are inspired by the following sources:
- The Art of Memory Forensics
- In the Land of MMUs: Multiarchitecture OS-Agnostic Virtual Memory Forensics
- Practical Memory Forensics
- What is Virtual Memory ? – All About Circuits
- What is huge pages in Linux – KernelTalks
- Translation Caching: Skip, Don’t Walk (the Page Table)
- Page Tables – The Linux Kernel
- Memory management in operating system – GeekforGeeks
- Exploring Virtual Memory and Page Structures – xenoscr.net
Patrick Ventuzelo / @Pat_Ventuzelo
Théo Abel / @theoabel_
About Us
Founded in 2021 and headquartered in Paris, FuzzingLabs is a cybersecurity startup specializing in vulnerability research, fuzzing, and blockchain security. We combine cutting-edge research with hands-on expertise to secure some of the most critical components in the blockchain ecosystem.
Contact us for an audit or long term partnership!
